Informatie Technologie op de PICU: doelstellingen en ambities
Informatie technologie speelt al een belangrijke rol in de direct medische zorg aan kritisch zieke kinderen aan jong volwassen op de Pediatrische Intensive Care Unit. De PICU kenmerkt zich door de extreme variatie in patiënten, vanaf de geboorte 2 kg tot aan jong volwassenen van 18 jaar met > 100 kg, en ziektebeelden. Dit maakt de zorg hoog complex en stelt unieke eisen aan een Patiënt Data Management Systeem (PDMS). Dit komt met name tot uiting op een aantal specifieke aspecten van het PDMS:
- Medicatie veiligheid
- Efficiency en kwaliteit van documentatie en
- Observationeel onderzoek en machine learning
1. Medicatie veiligheid
De meest voorkomende medische fouten en complicaties komen nog steeds voor bij het voorschrijven, bereiden en toedienen van medicatie, vocht en voeding.
Een recente analyse van de MIP database van het UMCU bevestigd dit ook.
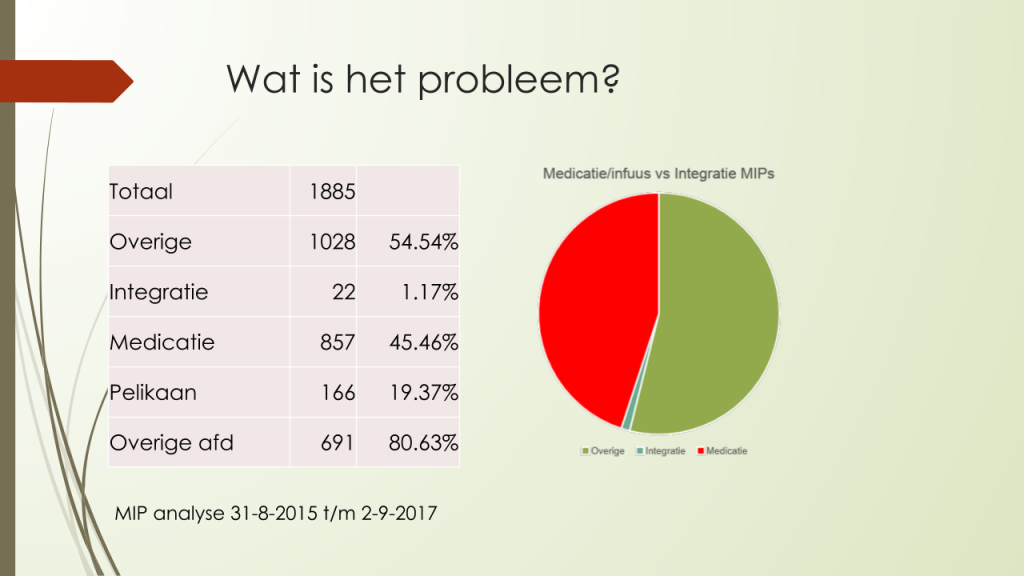
Problemen op het gebied van medicatie kunnen in elke proces van de medicatie cyclus plaats vinden.
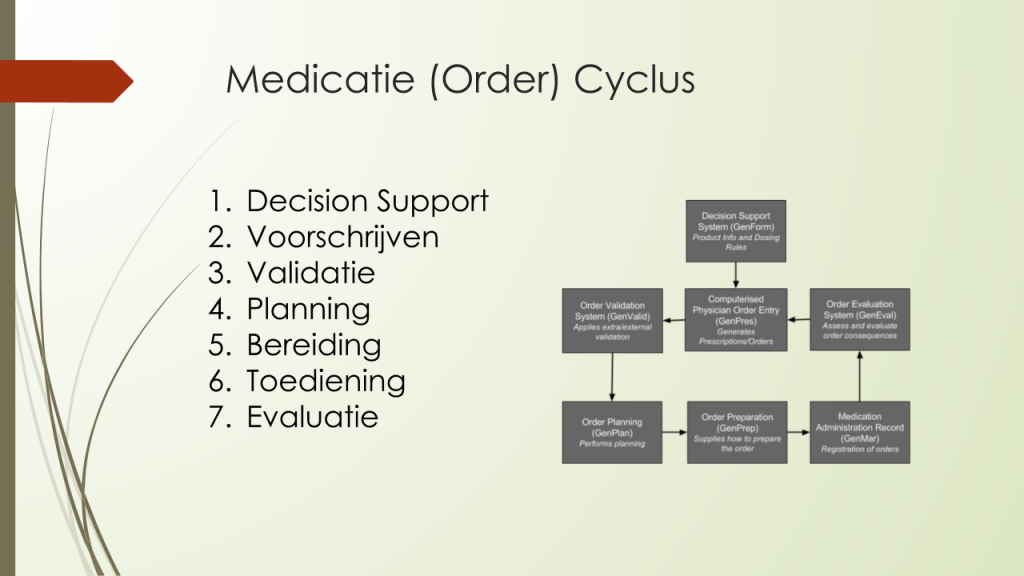
De processen die hierbij plaatsvinden zijn globaal te karakteriseren als:
- Opzoeken van de juiste informatie (kinderformularium, G-Standaard)
- Berekeningen (dosering en bereiding) en
- Identificatie (juiste patiënt, juist medicament, juiste toediening)
Al deze processen zijn zeer specifiek beschreven of te definiëren en zijn bij uitstek geschikt om uitgevoerd te worden door computers. Theoretisch zou eigenlijk hiermee het aantal medicatie fouten tot nagenoeg nul te reduceren zijn.
Doelstelling en ambities
- Het terugdringen van het aantal MIP meldingen op het gebied van medicatie tot < 5% van alle meldingen, met
- Behoud of zelfs toename van efficiency van het werkproces zodanig dat alle medische afspraken voor een patiënt in gemiddeld 10 minuten per patiënt kunnen worden geregeld.
2. Efficiency en kwaliteit van documentatie
De correcte documentatie van de klinische conditie van patiënten en de behandelingen en interventies zijn van groot belang voor:
- De overdracht van verantwoordelijkheid van zorg
- Klinische en medico-legale verantwoording en
- Het kunnen verrichten van observationeel wetenschappelijk onderzoek
De generatie en invoer bij het documenteren van patiënt gegevens mag echter de werk processen niet in de weg staan en geen belemmering vormen voor direct patiënten contact door zorgverleners. Dit laatste aspect is langere tijd onbelicht geweest maar krijgt steeds meer aandacht.
De kern aspecten van een kwalitatief goed en efficiënt documentatie systeem zijn:
- Gebruik maken van 1 databron zodanig dat verschillende invoer mogelijkheden gebruik maken van dezelfde databron. B.v. een gewicht dat kan worden ingevoerd via een verpleegkundige invoer scherm levert eenzelfde gewicht op als een gewicht ingevoerd in een verslaglegging van een lichamelijk onderzoek door een arts en vice versa.
- Integratie mogelijkheden van verschillende databronnen die gecombineerd kunnen worden. B.v. bij de documentatie van de infectiologische status van een patiënt moeten metingen met labwaarden, kweekuitslagen en antibiotica worden gecombineerd om een compleet plaatje te krijgen.
- Mogelijkheden tot data verificatie en filtering van data zodanig dat de validiteit en de kwaliteit van de documentatie wordt geborgd. B.v. uitfilteren of selecteren van de juiste temperatuur metingen.
Doelstelling en ambities
- Een complete dagelijkse status voering voor een patiënt is gemiddeld mogelijk binnen 15 minuten per patiënt.
- Een compleet overzicht van de actuele status, de probleem lijst, het korte termijn beleid, behandeldoelen, het lange termijn beleid en het chronologisch beloop van een patiënt is te verkrijgen in gemiddeld 5 minuten per patiënt.
- Overdracht en correspondentie is te genereren vanuit het systeem met minimale handmatige toevoegingen zodanig dat een brief en overdracht gemiddeld binnen 15 minuten per patiënt geregeld kunnen worden.
3. Observationeel onderzoek en machine learning
De klassieke wijze van verkrijgen van evidence, het verrichten van medisch epidemiologische onderzoek d.m.v. randomized controlled trials en prospectief cohort onderzoek bij specifieke patiënt populaties schiet in vele gevallen tekort om behandeling en onderzoek van individuele patiënten goed te onderbouwen. Deze vorm van onderzoek is vooral gericht op gemiddelde interventies in gemiddelde patiënt populaties waarbij gebrek aan homogeniteit de extrapolatie van bevindingen ernstig beperkt.
Een aanvullend alternatief om beter inzicht te krijgen in behandeling, diagnose en prognose bij individuele patiënten is het gebruik maken van de dagelijkse vastgelegde data van patiënten d.m.v. machine learning.
Om data geschikt te maken voor machine learning moet echter wel aan een aantal voorwaarden worden voldaan:
- Het aloude adagium “garbage in, garbage out” geldt ook voor machine learning. Data moet zo mogelijk aan de bron worden gefilterd en gevalideerd zodat alleen kwalitatief hoogwaardige data overblijft.
- Het format van de data moet worden aangepast om te zorgen dat machine learning algoritmes gebruik kan maken van data.
- Tot slot leidt ook bij machine learning algoritmes meer data (Big Data) tot preciezere en meer zekere uitkomsten. Daarvoor is bij poolen van data volgens wet en regelgeving ook vaak anonimisatie van data een vereiste.
Doelstellingen en ambities
- Het ontwikkelen van een software framework wat zorg draagt voor extractie, validatie en transformatie van alle meetgegevens, laboratorium waarden, diagnoses en interventies samen met relevante patiënt karakteristieken zodanig dat de gegenereerde data direct gebruikt kan worden voor observationeel onderzoek en machine learning.
- Het toepassen van dit framework op tenminste 3 onderzoeksprojecten met als resultaat een machine learning algoritme wat direct in de praktijk gebruikt kan worden en een aantoonbare meerwaarde heeft.
Tot slot
Het is belangrijk om te realiseren dat voor elke bovenstaande ambitie en doelstelling reeds minimaal een prototype implementatie gemaakt is waardoor de haalbaarheid van de ambitie en/of doelstelling kan worden aangetoond.