A Conceptual Framework for Medical Data
We need data for everything we do in clinical practice. Basically we need data for three things:
- To determine the current state of the patient, i.e. the diagnoses.
- To determine the expected state of the patient, i.e. the prognoses.
- And whether of not we can change the expected state of the patient with medical interventions. Resulting in an observed state, i.e. the outcome.
The relationship between these basic be depicted as follows:
To establish these basic clinical information items we need data. However the old adage: garbage in, garbage out, makes it difficult to reliably establish and classify these items.
In order to clean up the raw data stored in the various information sources in hospitals, a preprocessing of data is needed using:
- Conversions, to normalize data
- Filtering, to clean data and
- Aggregate, to turn data into clinically meaningful data (concepts)
These clinical data points (or more general events) are ordered in time.
The processing of raw data into clinically meaningful data concepts have been previously described in blogs about PICURED, the Pediatric Intensive Care Research Database initiative.
However, clinical data still is not the same as clinical information, in the sense that it has meaning or relevance to diagnoses, prognoses, interventions or outcome measures.
The accumulation of clinical information over time results into the establishment/reinforcement or adjustment of diagnoses, prognoses, interventions and observed outcomes.
The central theme is time. Time is literally of essence. The incremental recording of data over time and processing data over time is closely related in computer science to event processing and event sourcing. If you look at a prototypical event sourcing picture, there is a lot of common ground.
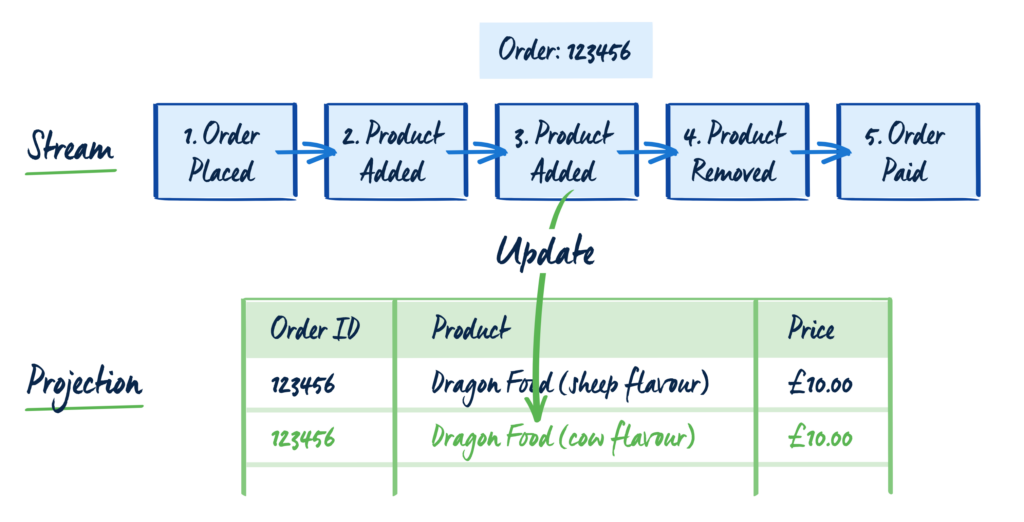
In conclusion, this Conceptual Framework for Medical Data could nicely fit in the Event Sourcing pattern of managing, processing and storing data.
![]()